
- 7. January 2026
- Posted by: Die Redaktion
- Category: READING TIPS
Survey and analysis of hallucinations in large language models – Study by Anh-Hoang, Tran & Nguyen
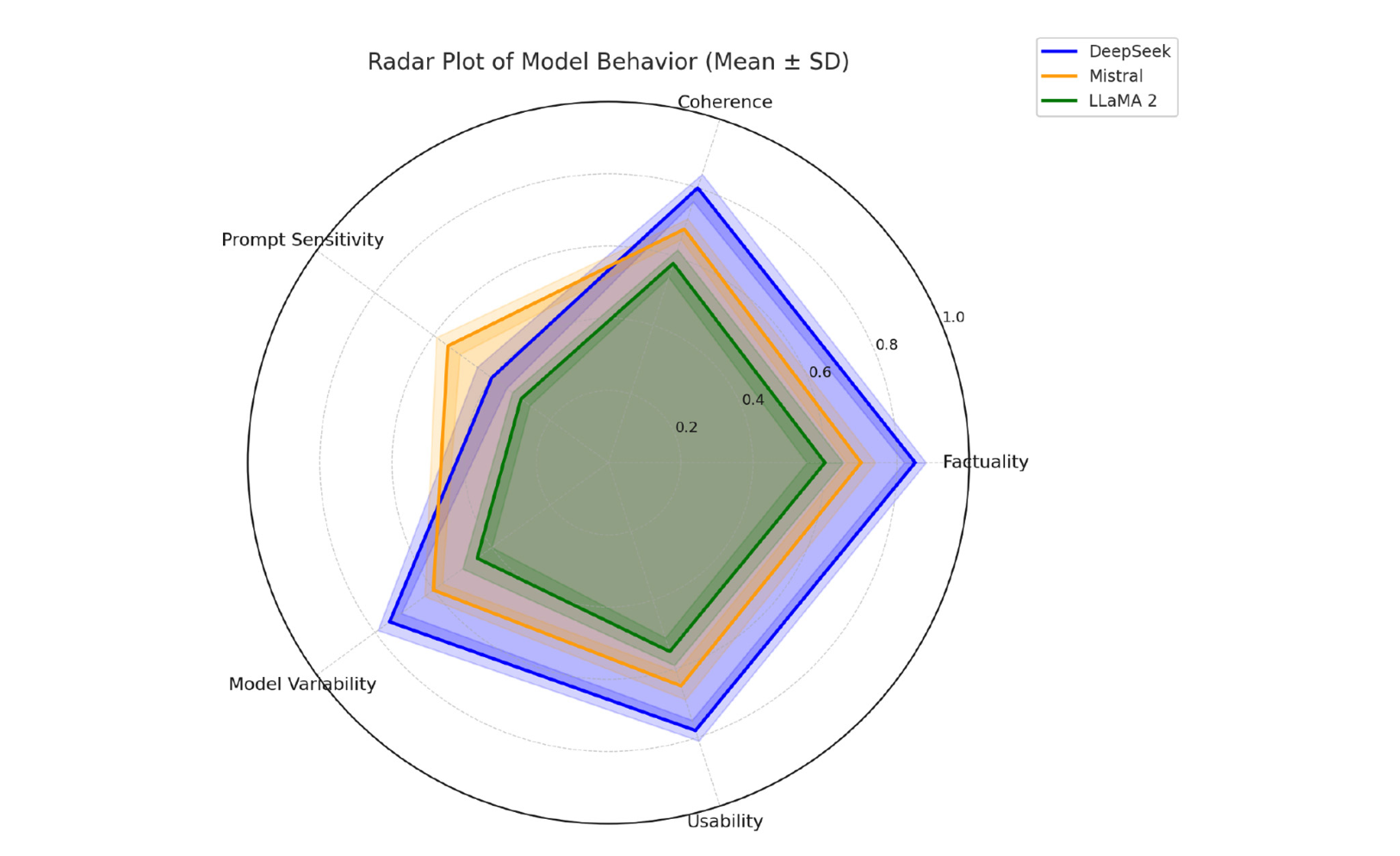
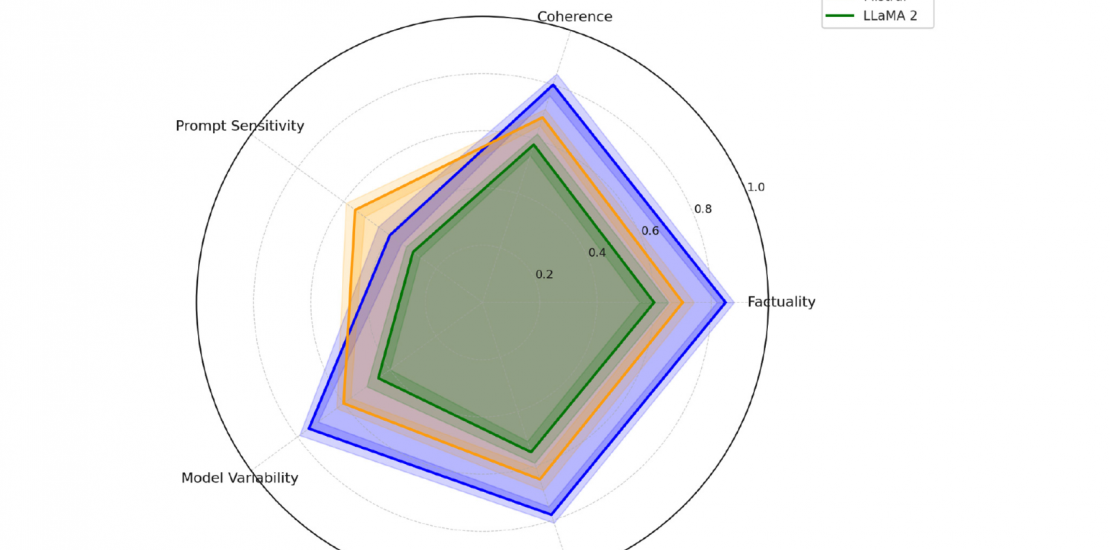
The study by Anh-Hoang, Tran and Nguyen, published in Frontiers in Artificial Intelligence in 2025, analyzes the problem of hallucinations in large language models (LLMs), i.e. false or unfounded statements presented as fact by AI systems. The aim of the work is to understand the extent to which such errors are influenced by the design of prompts and where the limits of prompting lie.
A key finding of the study is that the wording of prompts has a significant influence on the reliability of AI-generated responses. Unclear or ambiguous instructions significantly increase the probability of hallucinations. In contrast, structured, explicit and context-rich prompts lead to measurably better results. The use of chain-of-thought prompting, in which the AI is guided to think step by step, is particularly emphasized. This technique significantly reduces hallucinations in many models.
At the same time, the study clearly shows that prompting alone is not a panacea. With certain models, hallucinations occur even when the prompts are precise and well-structured. In these cases, the causes lie in factors internal to the model, such as training data or limited factual knowledge. The authors therefore emphasize that hallucinations can always have both prompt-dependent and model-related causes.
Overall, the study concludes that a reduction in hallucinations can only be achieved through the interaction of several measures. Prompt optimization is an effective but limited instrument that needs to be supplemented by model-side improvements and additional control mechanisms.
