
- 7. Januar 2026
- Veröffentlicht durch: Die Redaktion
- Kategorie: LESETIPPS
Survey and analysis of hallucinations in large language models – Studie von Anh-Hoang, Tran & Nguyen
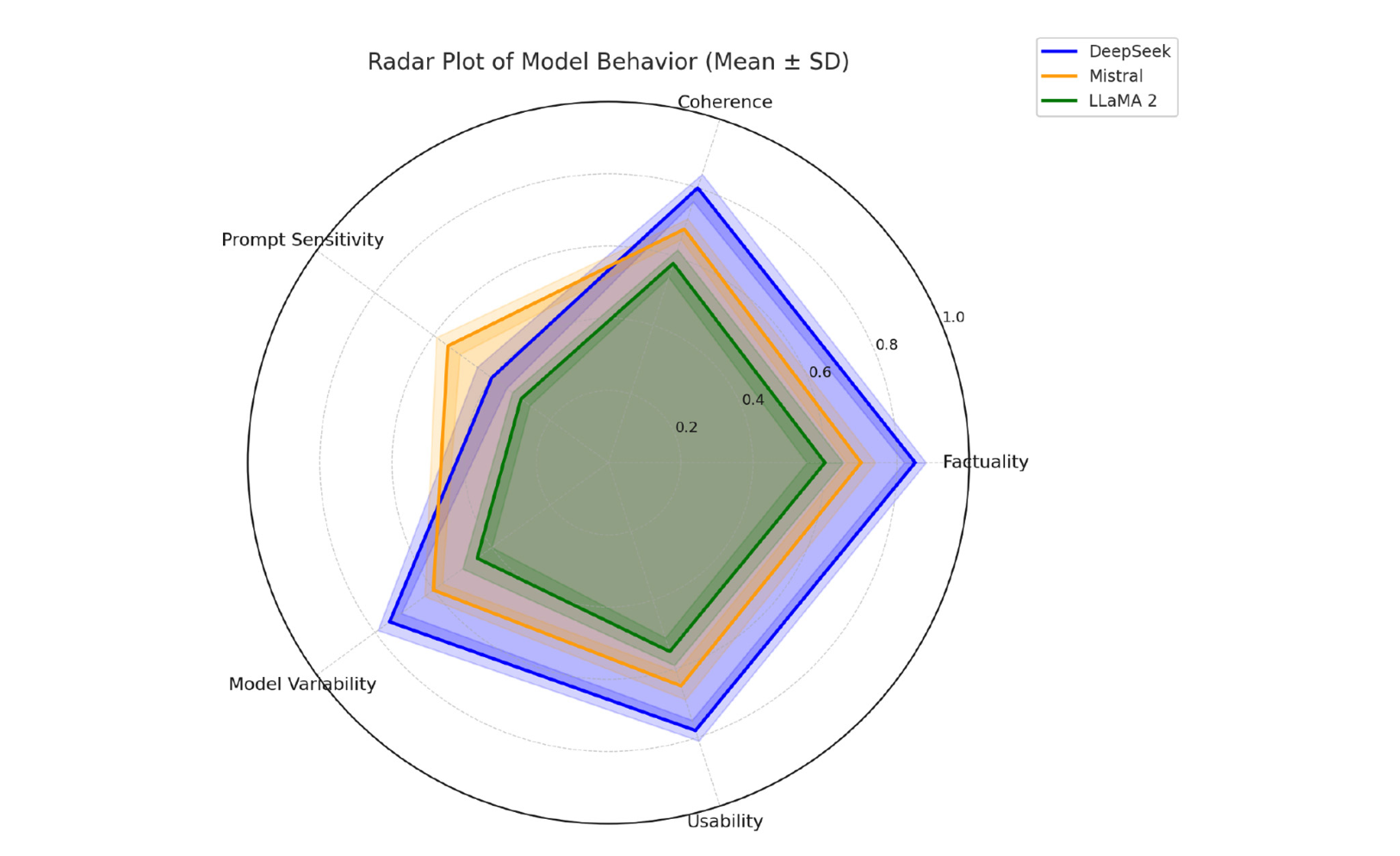
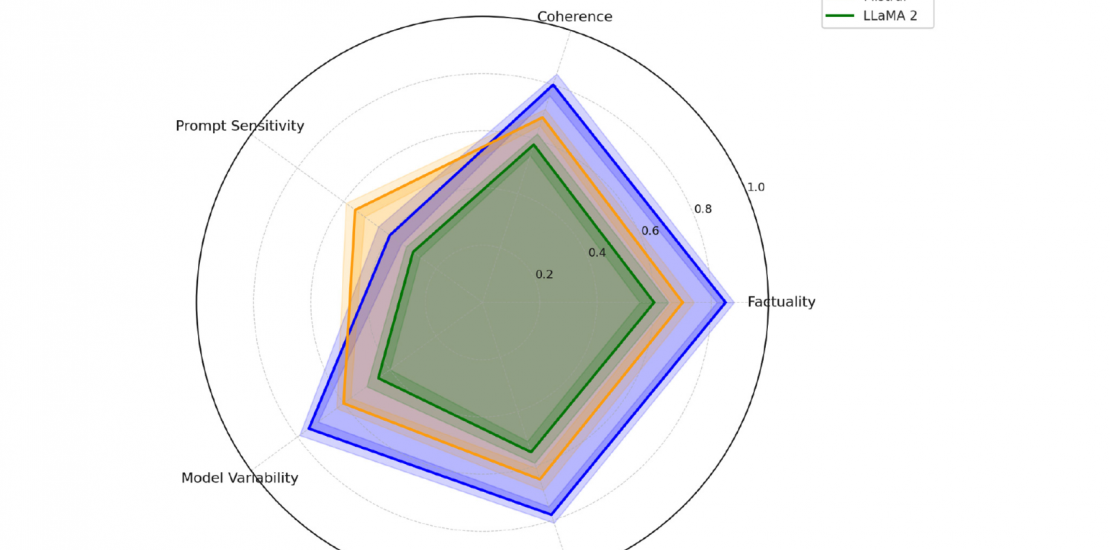
Die Studie von Anh-Hoang, Tran und Nguyen, veröffentlicht 2025 in Frontiers in Artificial Intelligence, analysiert das Problem von Halluzinationen in Large Language Models (LLMs) also inhaltlich falschen oder unbegründeten Aussagen, die von KI-Systemen als Fakt präsentiert werden. Ziel der Arbeit ist es zu verstehen, in welchem Ausmaß solche Fehler durch die Gestaltung von Prompts beeinflusst werden und wo die Grenzen des Promptings liegen.
Ein zentrales Ergebnis der Studie ist, dass die Formulierung von Prompts einen erheblichen Einfluss auf die Zuverlässigkeit von KI-generierten Antworten hat. Unklare oder mehrdeutige Anweisungen erhöhen die Wahrscheinlichkeit von Halluzinationen deutlich. Demgegenüber führen strukturierte, explizite und kontextreiche Prompts zu messbar besseren Ergebnissen. Besonders hervorgehoben wird der Einsatz von Chain-of-Thought Prompting, bei denen die KI zu schrittweisem Denken angeleitet wird. Diese Technik reduziert Halluzinationen bei vielen Modellen deutlich.
Gleichzeitig zeigt die Studie klar, dass Prompting allein kein Allheilmittel ist. Bei bestimmten Modellen treten Halluzinationen auch dann auf, wenn die Prompts präzise und gut strukturiert sind. In diesen Fällen liegen die Ursachen in modellinternen Faktoren wie Trainingsdaten oder begrenztem Faktenwissen. Die Autor:innen betonen daher, dass Halluzinationen immer sowohl promptabhängige als auch modellbedingte Ursachen haben können.
Insgesamt kommt die Studie zu dem Schluss, dass eine Reduktion von Halluzinationen nur durch das Zusammenspiel mehrerer Maßnahmen erreicht werden kann. Prompt-Optimierung ist ein wirksames, aber begrenztes Instrument, das durch modellseitige Verbesserungen und zusätzliche Kontrollmechanismen ergänzt werden muss.
